Highspeed mit Pokey-Divisor 0
von Dietrich » Sa 24. Jul 2010, 22:46Hi,
ich bastele gerade an meiner Highspeed-Routine herum (für ein QMEG-OS 4.1) und überlege, ob es sich lohnt, Übertragungen von mehr als 256 Byte auf einmal zu unterstützen und/oder Pokey-Divisor 0 zu unterstützen.
1) Gibt es eigentlich Geräte, die mehr als 256 Byte mit einem einzigen SIO-Komando übertragen? Bisher kenne ich nur das Laden der Highspeed-Routine von der Speedy, die etwas mehr als 500 Byte auf einmal überträgt.
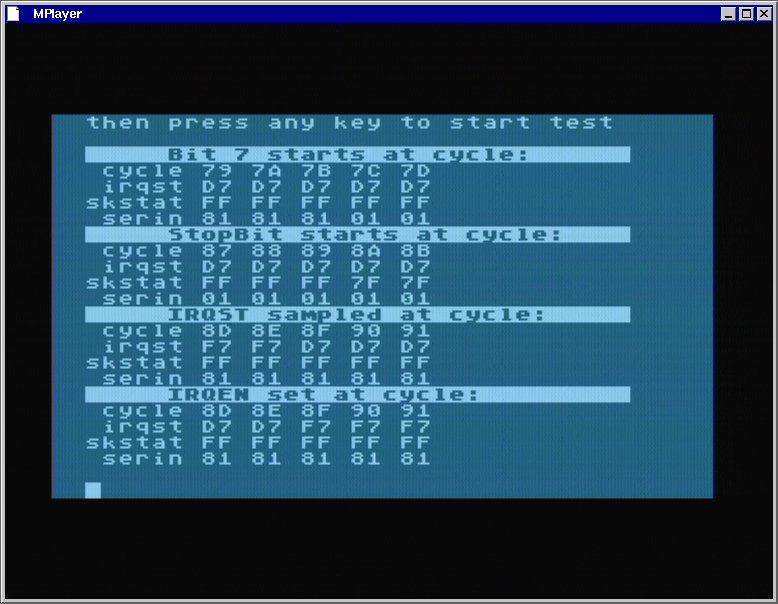
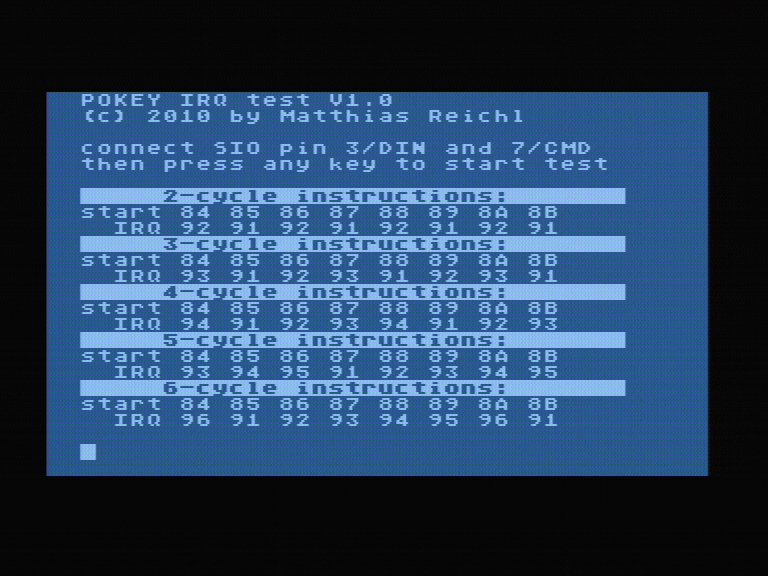
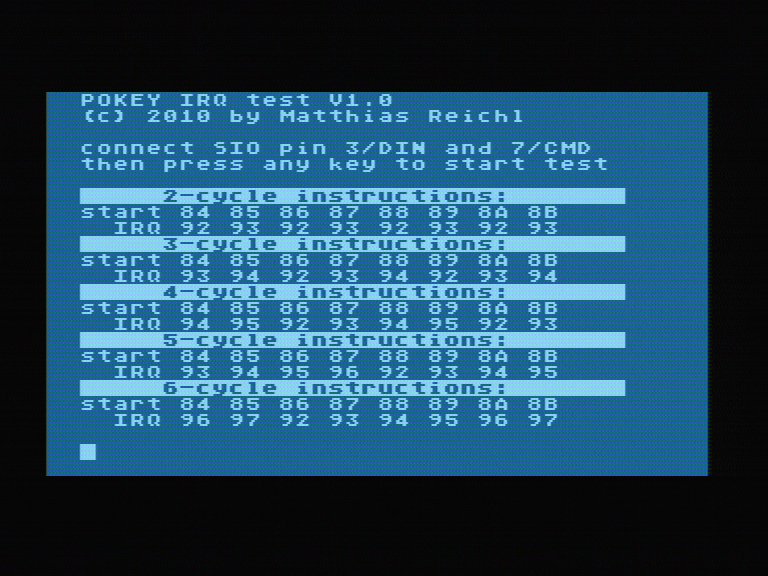
2) Bei Pokey-Divisor 0 (mit AspeQt) funktioniert meine Highspeed-Routine mit "kurzem" VBI mit einem ATARI, aber mit einem anderen stottert es öfters, obwohl es theoretisch gehen müsste. Mein VBI dauert max. 74 Takte, hinzu kommen 7 Takte für den NMI und 31 Takte für den System-NMI-Handler, macht zusammen 112 Takte. Nach meiner Rechnung sollte es aber sogar mit 148 Takten noch einwandfrei funktionieren. Zwar kann ich die VBI-Routine problemlos um 16 Takte kürzen (xitvbv nicht benutzen, Timerlogik umstellen), womit es dann auch läuft - ich würde aber schon gerne wissen, warum 112 Takte für den VBI bei Pokey-Divisor 0 zu viel sind.
Zur Berechnung: Wenn das letzte Byte vor dem VBI ankommt, befindet sich die Leseschleife beim Pollen (9 Takte). Insgesamt ist meine Leseschleife 67 Takte lang. Für das nächste Byte nach dem VBI kommen wieder 9 Takte pollen sowie 16 Takte für das Abholen und SERIN-IRQ rücksetzen. Dann noch 4 Takte bis der ATARI wieder auf den SERIN-IRQ reagieren kann. Macht zusammen 105 Takte + VBI. 2 Bytes bei Pokey Divisor 0 zu empfangen dauert 280 Takte, also weniger als 3 leere Scanlines und damit max. 27 Takte Refresh. Also bleiben für den VBI max. 280-105-27 = 148 Takte übrig.
@hwdoc: Danke für den Hinweis und das Entfernen der Kondensatoren. Da hätte ich wohl länger gesucht, warum es nur bisher nur bis Pokey-Divisor 3 ging ...
ich bastele gerade an meiner Highspeed-Routine herum (für ein QMEG-OS 4.1) und überlege, ob es sich lohnt, Übertragungen von mehr als 256 Byte auf einmal zu unterstützen und/oder Pokey-Divisor 0 zu unterstützen.
1) Gibt es eigentlich Geräte, die mehr als 256 Byte mit einem einzigen SIO-Komando übertragen? Bisher kenne ich nur das Laden der Highspeed-Routine von der Speedy, die etwas mehr als 500 Byte auf einmal überträgt.
2) Bei Pokey-Divisor 0 (mit AspeQt) funktioniert meine Highspeed-Routine mit "kurzem" VBI mit einem ATARI, aber mit einem anderen stottert es öfters, obwohl es theoretisch gehen müsste. Mein VBI dauert max. 74 Takte, hinzu kommen 7 Takte für den NMI und 31 Takte für den System-NMI-Handler, macht zusammen 112 Takte. Nach meiner Rechnung sollte es aber sogar mit 148 Takten noch einwandfrei funktionieren. Zwar kann ich die VBI-Routine problemlos um 16 Takte kürzen (xitvbv nicht benutzen, Timerlogik umstellen), womit es dann auch läuft - ich würde aber schon gerne wissen, warum 112 Takte für den VBI bei Pokey-Divisor 0 zu viel sind.
Zur Berechnung: Wenn das letzte Byte vor dem VBI ankommt, befindet sich die Leseschleife beim Pollen (9 Takte). Insgesamt ist meine Leseschleife 67 Takte lang. Für das nächste Byte nach dem VBI kommen wieder 9 Takte pollen sowie 16 Takte für das Abholen und SERIN-IRQ rücksetzen. Dann noch 4 Takte bis der ATARI wieder auf den SERIN-IRQ reagieren kann. Macht zusammen 105 Takte + VBI. 2 Bytes bei Pokey Divisor 0 zu empfangen dauert 280 Takte, also weniger als 3 leere Scanlines und damit max. 27 Takte Refresh. Also bleiben für den VBI max. 280-105-27 = 148 Takte übrig.
@hwdoc: Danke für den Hinweis und das Entfernen der Kondensatoren. Da hätte ich wohl länger gesucht, warum es nur bisher nur bis Pokey-Divisor 3 ging ...